"Corpus - the Virtual Native Speaker"
In the following I would like to tell you what we have done in class and how useful the working process with corpora was in real. The reflection will not be representative or generally true as we just tried out some activities in one session and as I do not use corpora on my own at home.
We basically looked at three different Corpora.
1. BNC (British National Corpus)
2. Time Corpus
3. WebCorp
I worked with the WebCorp but I will at least tell you how the BNC works. It is quite simple as you just have to go to www.http://www.natcorp.ox.ac.uk/ and then you immediately have access to the BNC. In a second step you type the word(s) you are looking for into the "look up-box" and click on "go".
What you get then are maximal 50 examples for how your word has been used in context. If you type in "high" e.g. in order to know when the word high is used compared to "tall" (you would have to check that word as well), you get 50 examples out of 38177 results. This is how the BNC in use looks like and how the results are presented to the user. This is just part of the list you get of course...
We basically looked at three different Corpora.
1. BNC (British National Corpus)
2. Time Corpus
3. WebCorp
I worked with the WebCorp but I will at least tell you how the BNC works. It is quite simple as you just have to go to www.http://www.natcorp.ox.ac.uk/ and then you immediately have access to the BNC. In a second step you type the word(s) you are looking for into the "look up-box" and click on "go".
What you get then are maximal 50 examples for how your word has been used in context. If you type in "high" e.g. in order to know when the word high is used compared to "tall" (you would have to check that word as well), you get 50 examples out of 38177 results. This is how the BNC in use looks like and how the results are presented to the user. This is just part of the list you get of course...

Results for 'high' in the BNC
If you click on the blue letters and numbers you will be linked to the source page so that you know where the sentence was taken from. That is also the way how to find out the register of the example. Below you see how the sources are presented. I chose the source for the first result A30.
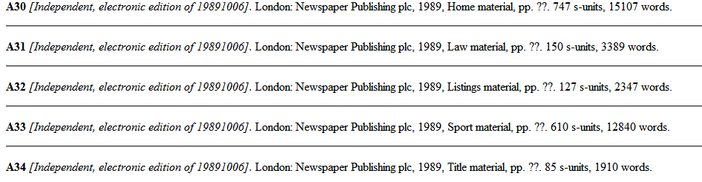
Sources of the individual results on BNC
I have to say that the number of results which you get is quite fgascinating and the sources provide access to authentic language material. Nevertheless, it would be better of the register of the examples would be given automatically as well so that you have a better overview. Now you have to read all the examples and then you have to find out when high is used rather than tall and so on ... In my point of view, it is time-consuming altough a good idea as such. The Corpus is just not targeted towards didactical/pedagogical usage for school.
BNC in a nutshell: The use is easy and the results are high in number which is a good aspect. Nevertheless, I think that the results are still too broad for students at school and I am wondering what I could type in in order to find out if "there is" is often used with a following plural or not. I tried different things but as the following words are always different it is kind of hard to get a satisfying result.
BNC in a nutshell: The use is easy and the results are high in number which is a good aspect. Nevertheless, I think that the results are still too broad for students at school and I am wondering what I could type in in order to find out if "there is" is often used with a following plural or not. I tried different things but as the following words are always different it is kind of hard to get a satisfying result.
Time Corpus was another choice we had. The corpus provides more than 100 million words from the 1920s until the 2000s. Go to http://corpus.byu.edu/time/ to access the page. As we worked with WebCorp I had to work with this corpus on my own and I tried to find out how it works. In my opinion, it offers the most choices regarding the selection process and narrowing of the research. Nevertheless, I think it is the most complicated one which you have to study in detail in order to know how it works.
But let’s come to another corpus, namely the WebCorp which I used in class last week and which can be accessed under http://www.webcorp.org.uk/. How does it work? Bascially, you just type in the term you want to do research on, e.g. "high". You can enter a word, phrase or pattern. Additionally, you have to select the search engine (e.g.Alta Vista/Yahoo, Bing, Open Directory or Google), the concordance span (one up to 20 words to left and right) and the case option (sensitive or insensitive). Then you have to click on submit and that's it.
Then you get a number of examples, maximally 64 when using google as the search engine (it may differ!!), in which high is used. The sentences are structured according to their webpages which you can also directly click on and access. That means that you automatically see where the sentence comes from (e.g. wikipedia). This gives a better overview than the BNC does. In addition, you can click on the plain text or a word list. I tried both but is rather confusing to me, at least the plain text. The list of words could eventually be useful in order to find out which words are being used in the context as well but I generally dislike these two options.
WebCorp in a nutshell: As the BNC, WebCorp is also not targeted towards didactical issues. The possibility to select certain things at first is quite good and the structure of the presentation of the results is better. The fact that it is immediately clear where the sentences come from may help to exclude certain results from the very beginning if they seem to be unreliable. But all in all, the output is touching an information overload and some examples are more confusing than helpful.
But let’s come to another corpus, namely the WebCorp which I used in class last week and which can be accessed under http://www.webcorp.org.uk/. How does it work? Bascially, you just type in the term you want to do research on, e.g. "high". You can enter a word, phrase or pattern. Additionally, you have to select the search engine (e.g.Alta Vista/Yahoo, Bing, Open Directory or Google), the concordance span (one up to 20 words to left and right) and the case option (sensitive or insensitive). Then you have to click on submit and that's it.
Then you get a number of examples, maximally 64 when using google as the search engine (it may differ!!), in which high is used. The sentences are structured according to their webpages which you can also directly click on and access. That means that you automatically see where the sentence comes from (e.g. wikipedia). This gives a better overview than the BNC does. In addition, you can click on the plain text or a word list. I tried both but is rather confusing to me, at least the plain text. The list of words could eventually be useful in order to find out which words are being used in the context as well but I generally dislike these two options.
WebCorp in a nutshell: As the BNC, WebCorp is also not targeted towards didactical issues. The possibility to select certain things at first is quite good and the structure of the presentation of the results is better. The fact that it is immediately clear where the sentences come from may help to exclude certain results from the very beginning if they seem to be unreliable. But all in all, the output is touching an information overload and some examples are more confusing than helpful.
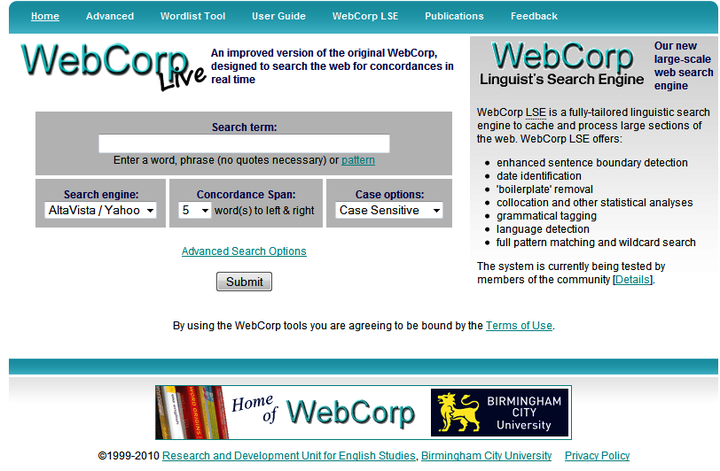
WebCorp Starting Page

Output for query 'high' (WebCorp)
We had a couple of tasks to work on of which I want to present a few here shortly:
Is it true that “fate” is always used in genitive contexts and “destiny” in positive ones? (No)
Which sentence is correct: “She has proven her theory” or “She has proved her theory”? (1. AmE, 2. BrE)
Does “public viewing” actually exist in English? (Yes, but it has a totally different meaning!)
Is there a meaning difference between tall and high? (They are used in different contexts)
Can only a singular noun follow "there’s"? (No)
…
These questions and some more had to be answered using a corpus. It was relatively easy to get the answers although there were some questions we had to think about longer as the evidence did not become clear immediately after having consulted the corpus.
What we generally said in class was that Corpus work is mainly useful for showing how English is actually used in written and spoken English by native speakers regarding lexico- and grammatical patterns. I di agree with that fact but I think that the results you get are sometimes confusing or not very reliable, e.g. if you rely on Wikipedia results. You have to be very careful what results you want to stick to. But in general, it is true that corpora give us example of collocation (routines combination of words) and colligation (routine co-occurrence of grammatical choice). The investigation of these two issues is what makes the work with a corpus useful.
Here are the advantages and disadvantages of using corpora (some have been mentioned in class already):
Advantages
+ Students get in touch with authentic material
+ Motivation will increase due to the fact that the language is “real”
+ Useful for non-native teachers as they get excellent information about how language is actually used
+ Comfortable learning environment
+ Learner-centered
+ Descriptive rather than prescriptive
+ Goes along with the three goals of learning: accuracy, fluency and restructuring
+ Raising awareness that there is not the ONE native speaker, but that English is spoken and used differently throughout the world
+ Chance to encounter the “real” grammar book and therefore coming closer to how English is being used today
+ Up-to-date material
+ Motivation will increase due to the fact that the language is “real”
+ Useful for non-native teachers as they get excellent information about how language is actually used
+ Comfortable learning environment
+ Learner-centered
+ Descriptive rather than prescriptive
+ Goes along with the three goals of learning: accuracy, fluency and restructuring
+ Raising awareness that there is not the ONE native speaker, but that English is spoken and used differently throughout the world
+ Chance to encounter the “real” grammar book and therefore coming closer to how English is being used today
+ Up-to-date material
Disadvantages
- As the internet provides so many different texts with different and not always reliable authors, one has to be careful which source to trust or not.
- There could be an information overload in which the students miss the wood for the trees
- It is often considered a “hardcore linguistics” method
- It takes time to understand how a corpus works and to familiarize students with it. In my opinion, the explanation of the TimeCorpus would take much longer than the WebCorp or the BNC
- Tools are new to the students which can lead to uncertainty
- Maybe native speakers are not the ideal for English learners and the traditional textbooks and grammar books provide a better basis than native speaker material
- Maybe just useful for more advanced learners
- There could be an information overload in which the students miss the wood for the trees
- It is often considered a “hardcore linguistics” method
- It takes time to understand how a corpus works and to familiarize students with it. In my opinion, the explanation of the TimeCorpus would take much longer than the WebCorp or the BNC
- Tools are new to the students which can lead to uncertainty
- Maybe native speakers are not the ideal for English learners and the traditional textbooks and grammar books provide a better basis than native speaker material
- Maybe just useful for more advanced learners
Taking everything into consideration, I come to the conclusion that what I have read about corpora in theory was, to be honest, more convincing than its actual use.
I think the basic problem is the way these corpora look like and work – they should be structured in another way, taking the use at school into consideration. The results are too broad in my opinion. The functionality is what I don’t really like as the output is not as narrowed and obvious as it should be. Nevertheless, I would use a simple corpus (WebCorp) for older students. The reason is simple: I would not use it with the younger students who just started to learn the English language. I am sure that they need the traditional grammar book reference with which they achieve confidence and a feeling of security. They would be confused if they saw that you can say “There is many books in there” and “There are many books in there”. Children need fixed rules at the beginning in order to build a basis for their language career. When they are older and more advanced, it makes sense to work with authentic material and look for how English is really used in reality. Older students can handle the fact that some rules seem to be totally out of use and they should gain a feeling for the English language. At the latest if they will get in touch with people from abroad they will notice that not everything they prescriptively learned at school is actually used that way. That is why I think using corpora should be integrated into class, e.g. in the Oberstufe when the main grammar issues have been taught already, although the corpora websites available online definitely have to be restructured and reconsidered.
It is always the best solution to find a balance between teaching traditionally, especially with the younger students as they need rules, and in a contemporary way taking authentic material of a corpus for example into consideration as well.
added: December 05, 2010
